
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- flex기본
- 리커젼
- AWS기초
- css기초
- 개발툴
- complexity
- 스코프
- AWS조사
- 클로저
- 메모이제이션
- CSS
- prototype
- APPEND
- node.js설치
- vscode
- node.js
- scope
- 재귀함수
- AWS
- IT
- var
- 생활코딩
- 코드스테이츠
- 인터프리터
- JavaScript
- 원본과 복사본
- Big-O notation
- 기초공부
- appendChild
- let
Archives
- Today
- Total
Jveloper
S3, EC2, RDS 실습전 자료조사 본문
Amazon EC2
Amazon Elastic Compute Cloud(Amazon EC2)란? AWS의 대표적인 상품이며 여러가지 서비스들중에서 가장 중요하고 가장 먼저 생겨난 서비스이며 상품들 중에서 가장 범용적인 기능을 가지고있다. 간단히 말하면 ec2는 가상의 컴퓨터를 제공해주며 이 컴퓨터는 원격으로 제어가 가능하다.
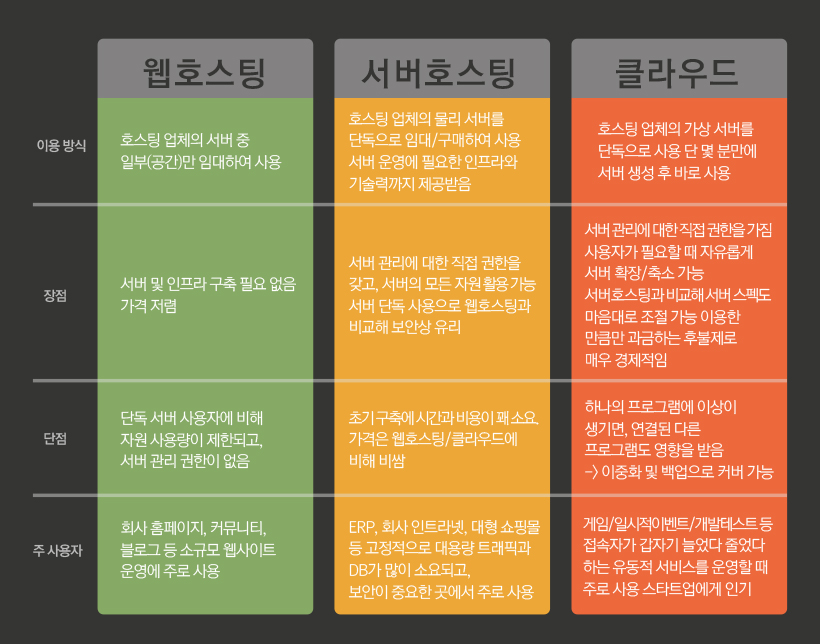
*기존의 서버호스팅과 클라우드 서비스의 차이점
1. EC2에서 제공하는 기능
Instance: "가상 컴퓨터 환경 제공(쉽게 말해 컴퓨터 한대를 빌려준다)"
AMI(amazon machine image): "서버에 필요한 운영체제, 소프트웨어들로 쉽게 구성하여 인스턴스를 제공"
Instance Type: "인스턴스를 위한 CPU, Memory, Storage, Networking 용량 구성을 제공"
Key Pair: "인스턴스 로그인 정보 보호. 퍼블릭 키 암호화 기법을 사용하여 로그인 정보를 암호화 및 해독한다."
Instance Store Volume: "임시 데이터를 저장(인스턴스 종료시 삭제 된다)"
Amazon Elastic Block Store(Amazon EBS): "영구적으로 Storage Volume에 데이터를 저장"
Access room?: "인스턴스와 아마존 EBS 등의 리소스를 다른 물리적 장소에서 데이터를 관리 구역 및 공간"
Configue security Group: "보안과 관련된 항목을 지정하는 기능이며 인스턴스에 연결할 수 있는 프로토콜, 포트, 소스 IP 범위를 지정하는 방화벽같은 역할을 한다. 네트워크를 알아야 이 기능을 잘 사용할 수 있다.(IP, 도메인, port 등등)"
EIP: "동적 클라우드 컴퓨팅을 위한 고정 IPv4 주소"
Tag Instance: "사용자가 생성한 인스턴스에대한 설명을 붙일 수 있다. 구체적으로 말하자면 Tag란? 만든 Instance가 어떠한 역할인지 관리자가 누구인지 메모하고싶을 때 사용하는 서비스이다."
Virtual Private Clouds(VPC): "눈에 보이지 않지만 원격으로 고객의 네트워크와 간편하게 연결할 수 있는 가상 네트워크"2. EC2를 사용하여 할 수 있는 일들
1. 웹 서비스를 할 수 있다.
2. 빅데이터 시스템을 설치후 거대한 데이터를 처리 가능.
3. mac인데 윈도우를 사용해야할때 윈도우를 만들어서 인터넷 뱅킹을 할 수 있다.3. 장점
"탄력성 있는 웹 스케일 컴퓨팅"
Amazon EC2를 사용하면 몇 시간 또는 며칠이 아닌 몇 분 내에 용량을 늘리거나 줄일 수 있다. 한 개, 수백 개 또는 수천 개의 서버 인스턴스를 동시에 지정할 수 있다. 또한 [Amazon EC2 Auto Scaling]을 통해 EC2 플릿의 가용성을 유지하고 필요에 따라 집합을 자동으로 확장 및 축소하여 성능을 극대화하고 비용을 최소화할 수 있다.
"완전제어"
루트 액세스 및 상호 작용 기능을 포함하여 다른 머신에서와 같이 인스턴스를 완전히 제어할 수 있다. 부팅 파티션에 데이터를 보관한 채로 인스턴스를 중지한 다음 나중에 웹 서비스 API를 사용하여 동일한 인스턴스를 다시 시작할 수 있다. 웹 서비스 API를 사용하여 인스턴스를 원격으로 재부팅할 수 있으며, 콘솔 출력에도 액세스할 수 있다.
"유연한 클라우드 호스팅 서비스"
여러 인스턴스 유형, 운영 체제 및 소프트웨어 패키지를 선택할 수 있다. Amazon EC2를 사용하면 선택한 운영 체제 및 애플리케이션에 가장 적합한 메모리 구성, CPU, 인스턴스 스토리지, 부팅 파티션 크기를 선택할 수 있다. 예를 들어, 다양한 Linux 배포와 [Microsoft Windows Server]를 운영 체제로 선택할 수 있다.
"통합성"
Amazon EC2는 Amazon Simple Storage Service(Amazon S3), Amazon Relational Database Service(Amazon RDS) 및 Amazon Virtual Private Cloud(Amazon VPC) 등의 대부분의 AWS 서비스와 통합되어 있어, 컴퓨팅, 쿼리 처리 및 광범위한 애플리케이션 간 클라우드 스토리지에 대해 완전하고 안전한 솔루션을 제공한다.
"안정성"
Amazon EC2는 교체 인스턴스를 빠르고 예측 가능하게 실행할 수 있는 매우 안정적인 환경을 제공하며 이 서비스는 Amazon의 입증된 네트워크 인프라와 데이터 센터 내에서 실행된다. Amazon EC2 서비스 수준 계약은 각 Amazon EC2 리전에 대해 99.99%의 가용성을 보장한다.
"보안"
Amazon EC2는 Amazon VPC와 함께 작동하여 사용자 컴퓨팅 리소스에 보안성 및 강력한 네트워킹 기능을 제공한다.
"저렴한 비용"
Amazon EC2는 Amazon 규모에 따른 비용 측면적 절감 효과를 제공하며 실제로 소비하는 컴퓨팅 파워에 비해 매우 저렴하다.AWS S3(Simple Storage Service)
1. S3란 무엇일까?
Simple Storage Service 즉, 간단하게 데이터를 저장할 수 있도록 도와주는 서비스이다. S3를 이용해 데이터를 저장, 검색, 수정도 가능하다고 하는데 어떻게 이것이 가능한 것 일까?2. S3의 구성
2-1) 데이터의 바구니 '버킷'
'버킷'은 데이터가 저장되는 공간이다.
모든 '버킷'이 이름이 똑같다면, 구분이 힘들기 때문에 파란바구니, 빨간바구니 처럼 '고유의 이름'을 정할 수 있는 기능이 있다. 또한 이 안의 정보를 아무나 볼 수 없도록 '권한'을 설정 할 수가 있다. '버킷'은 맘대로 삭제하고 생성 할 수 도 있는데, 주의 할 점 은 삭제 후 같은 버킷을 재생성 하기 위해서는 매우 까다로운 과정을 거쳐야한다.
예를 들어, 기존에 사용하고 있던 빨간바구니를 버렸는데, 다시 사용하기 위해서는 마트에 가서 같은 제품을 사와야하는 번거로운 과정이 있다고 보면 된다.
따라서, '버킷'을 삭제할 때 는 '버킷' 자체를 삭제하기 보다는, 내부의 데이터를 다 지우고 기존의 '버킷'을 새 '버킷'을 사용하는 것 처럼 사용하는 것이 권장된다.
AWS는 매우 큰 용량의 바구니들을 제공한다. 하나의 바구니 안에는 무한에 가까운 정보들을 넣을 수 있다.. 2-2) 버킷에 담기는 데이터 '객체'
바구니에 담기는 데이터는 객체안에 담긴다. "즉 키 : value 페어의 형태로 담긴다!"
매우 큰 AWS의 버킷 용량 답게, "하나의 객체안에 최대 5TB의 용량의 데이터가 저장이 가능하다.(돈을 더 내면 한 객체 안에 더더더더 많은 데이터를 저장할 수 있다!!)"
그럼 왜 객체를 사용했을까? 라고 의문을 가질 수 있다. 자바 스크립트에서 객체는 주소값을 '참조'하여 사용한다. 즉, 다른곳에서 원본을 사용하지 않고 원본의 '복사본'을 사용한다는 뜻이다. S3에서 "객체를 사용하는 것도 비슷한 이유로, 원본의 손상을 막기 위해서이다."
아무리 관리 잘한 문서들도, 사람들의 손이 닿기 시작하면 변질되는 것 처럼 데이터들도 많은 접근이 있거나, 변동이 있다면 언젠가는 닳기 마련일 것이다.
하지만 복사본을 준다면, "원본의 내용을 그대로 볼 수도 있으면서 원본의 손상은 최대한으로 줄일 수 있을 것이다."
원본데이터의 생성 및 삭제만 지원하고 수정하는 기능은 지원하지 않는데, 수정하는 것과 비슷한 기능으로는 '덮어쓰기'가 있다.
"이 덮어쓰기는 원본을 다른 원본으로 바꾸는 작업이기 때문에, 빠르지는 않다고 한다. 이점 주의 할 것!"
또한 HTTP요청이나 데이터의 접근, 생성 등의 정보를 지닌 객체또한 존재 한다고 한다. 이를 이용해 버전관리가 용이하다.3. 어떻게 사용하나요?
만약 '김태훈'이라는 이름의 s3 '버킷'에 '몸무게'라는 데이터를 가지고 오고싶다면 김태훈.s3.amazonaws.com/몸무게 이런 식으로 버킷과 데이터 사이의 구분을 / 를 이용해 구분지어준다.
이걸 보내야하는데, s3는 https방식을 이용해 요청을 보내며, REST API를 이용한다.
따라서, '김태훈'이라는 이름의 s3 '버킷'에 '몸무게'라는 데이터를 가지고 오고싶다면
`https://김태훈.s3.amazonaws.com/몸무게 를 GET요청을 보내면 아마존에서 데이터를 보내준다.`4. 중요한 데이터가 있는데 이건 공개하고 싶지 않아요!
이런 경우에는 s3에서 정해놓은 다양한 '저장 클래스'를 이용하면 되는데
우리가 일반적으로 파일에도 접근 권한을 설정 해 놓는 것 처럼, 저장클래스를 다르게 설정하면 일정 비용을 내고 높은권한으로 데이터를 저장하는 것이 가능하다.
이것은 버킷단위로 설정할 수도 있고, 객체 혹은 데이터로도 설정이 가능하다. | STANDARD | 자주 액세스하는 데이터 | 99.999999999% | 99.99% | >= 3 | 없음 | 없음 | 없음 |
|---|---|---|---|---|---|---|---|
| STANDARD_IA | 수명이 길고 자주 액세스하지 않는 데이터 | 99.999999999% | 99.9% | >= 3 | 30일 | 128KB | GB당 검색 요금이 적용됩니다. |
| INTELLIGENT_TIERING | 변경 또는 알 수 없는 액세스 패턴으로 수명이 긴 데이터 | 99.999999999% | 99.9% | >= 3 | 30일 | 없음 | 객체당 모니터링 및 자동화 비용이 적용됩니다. 검색 요금이 없습니다. |
| ONEZONE_IA | 수명이 긴 데이터에 자주 액세스하지 않는 중요하지 않은 데이터 | 99.999999999% | 99.5% | 1 | 30일 | 128KB | GB당 검색 요금이 적용됩니다. 가용 영역의 손실에 대한 복원력이 없습니다. |
| GLACIER | 분에서 시간 단위로 검색 시간을 지원하는 장기간 데이터 보관 | 99.999999999% | 99.99%(객체 복원 후) | >= 3 | 90일 | 없음 | GB당 검색 요금이 적용됩니다. 이 객체에 액세스하려면 먼저 보관된 객체를 복원해야 합니다. 자세한 내용은 보관된 객체의 복원 단원을 참조하십시오. |
| DEEP_ARCHIVE | 12시간의 기본 검색 시간으로 거의 액세스하지 않는 데이터 아카이빙 | 99.999999999% | 99.99%(객체 복원 후) | >= 3 | 180일 | 없음 | GB당 검색 요금이 적용됩니다. 이 객체에 액세스하려면 먼저 보관된 객체를 복원해야 합니다. 자세한 내용은 보관된 객체의 복원 단원을 참조하십시오. |
| RRS(권장되지 않음) | 자주 액세스하는 중요하지 않은 데이터 | 99.99% | 99.99% | >= 3 | 없음 | 없음 | 없음 |
RDS(Relational Database Service)
클라우드에서 관계형 데이터베이스를 더 쉽게 설치, 운영 및 확장할 수 있는 웹 서비스입니다
MySQL, Oracle, SQL Server, PostgreSQL, MariaDB, Aurora(MySQL과 호환)을 비롯한 총 6가지 데이터베이스 엔진을 지원하고 있습니다.
*RDS의 장점 *
1. 관계형 데이터베이스
2. 쉽고 빠른 구성
3. 반복적인 관리작업을 대신 수행
4. 다양한 관계형 데이터베이스 옵션 제공
5. 쉽고 빠른 확장
6. 손쉬운 고 가용성 구성사용가능한 DB제품



그렇다면 RDS의 단점은 어떤것이 있을까?
1. 비용
RDS와 EC2의 비슷한 스토리지를 비교할 경우 RDS가 EC2보다 약 40~68% 정도 비싸다고 합니다.
IDC를 운영하기 위해서는 다른 요소들이 많기 때문에 절대적으로 비싸다고 단정하기는 어렵습니다.
(서버의 감가상각, DBA, SE, NE 등 운영자 비용, 전기비용, 상면비용, 모니터링 인력 비용 등)
다만 "인프라 신경 안쓰고 개발에만 집중하고 싶다" 라고 생각할 때 "비용대비 이점이 있다" 정도로 이해하시면 될 것 같습니다.2. 서버 접속불가
서버(aws측의 DB가 저장되는 곳(?))에 접속이 안됩니다. 따라서 문제가 발생했을 시에 자세한 것을 알기 위해서는 AWS 측에 SR을 올리는 방법 밖에 없게 됩니다. DBA의 역할이 크게 줄어드는 부분입니다.3. 권한제한, 제약사항들 등등

그래서 RDS가 정확히 뭘 하는데?
1. 내가 로컬 호스트 환경에서 깔아서 하던 그 DB를 클라우드 상에서 제공하는 것이 핵심이다
**S3**는 파일 서비스를 클라우드화 한 것이라면, **RDS**는 DB를 클라우드화 한 것
2. 아래 영상을 참고하면 확 이해가 갈거라고 생각한다
https://youtu.be/yjH10T3Miag : aws 에서 공식적으로 내놓은 RDS에 대한 설명 영상 링크
3. 또 중요한 기능인 **<백업 & 복원>** 
핵심은 저장을 하든 뭘 하든 준비된 또다른 DB에 똑같은 CUD를 하고 만일 하나가 죽었을 시에(어떤 이유에서든) 스탠바이 하고 있던 쌍둥이 DB를 바로 활용하는 것이다
다른 백업 기능으로는 Snapshot이라는것도 있다
Comments